9.2 The Standard Model of Speech Production
Dinesh Ramoo
Speech production falls into three broad areas: conceptualization, formulation and articulation (Levelt, 1989). In conceptualization, we determine what to say. This is sometimes known as message-level processing. Then we need to formulate the concepts into linguistic forms. Formulation takes conceptual entities as input and connects them with the relevant words associated with them to build a syntactic, morphological, and phonological structure. This structure is phonetically encoded and articulated, resulting in speech.
During conceptualization, we develop an intention and select relevant information from the internal (memory) or external (stimuli) environment to create an utterance. Very little is known about this level as it is pre-verbal. Levelt (1989) divided this stage into microplanning and macroplanning. Macroplanning is thought to be the elaboration of a communication goal into subgoals and connecting them with the relevant information. Microplanning assigns the correct shape to these pieces of information and deciding on the focus of the utterance.
Formulation is divided into lexicalization and syntactic planning. In lexicalization, we select the relevant word-forms and in syntactic planning we put these together into a sentence. In talking about word-forms, we need to consider the idea of lemmas. This is the basic abstract conceptual form which is the basis for other derivations. For example, break can be considered a lemma which is the basis for other forms such as break, breaks, broke, broken and breaking. Lemma retrieval used a conceptual structure to retrieve a lemma that makes syntactic properties available for encoding (Kempen & Hoenkamp, 1987). This can specify the parameters such as number, tense, and gender. During word-form encoding, the information connected to lemmas is used to access the morphemes and phonemes linked to the word. The reason these two processing levels, lemma retrieval and word-form encoding, are assumed to exist comes from speech errors where words exchange within the same syntactic categories. For example, nouns exchange with nouns and verbs with verbs from different phrases. Bierwisch (1970), Garrett (1975, 1980) and Nooteboom (1967) provide some examples:
- “… I left my briefcase in the cigar”
- “What we want to do is train its tongue to move the cat”
- “We completely forgot to add the list to the roof”
- “As you reap, Roger, so shall you sow”
We see here that not only are the exchange of words within syntactic categories, the function words associated with the exchanges appear to be added after the exchange (as in ‘its’ before ‘tongue’ and ‘the’ before ‘cat’). In contrast to entire words (which exchange across different phrases), segment exchanges usually occur within the same phrase and do not make any reference to syntactic categories. Garrett (1988) provides an example in “she is a real rack pat” instead of “she is a real pack rat.” In such errors, the segments involved in the error often share phonetic similarities or share the same syllable position (Dell, 1984). This suggests that these segments must be operating within some frame such as syllable structure. To state this in broader terms, word exchanges are assumed to occur during lemma retrieval, and segment exchanges occur during word-form encoding.
Putting these basic elements together, Meyer (2000) introduced the ‘Standard Model of Word-form Encoding’ (see Figure 9.2) as a summation of previously proposed speech production models (Dell, 1986; Levelt et al., 1999; Shattuck-Huffnagel, 1979, 1983; Fromkin, 1971, 1973; Garrett, 1975, 1980). The model is not complete in itself but a way for understanding the various levels assumed by most psycholinguistic models. The model represents levels for morphemes, segments, and phonetic representations.
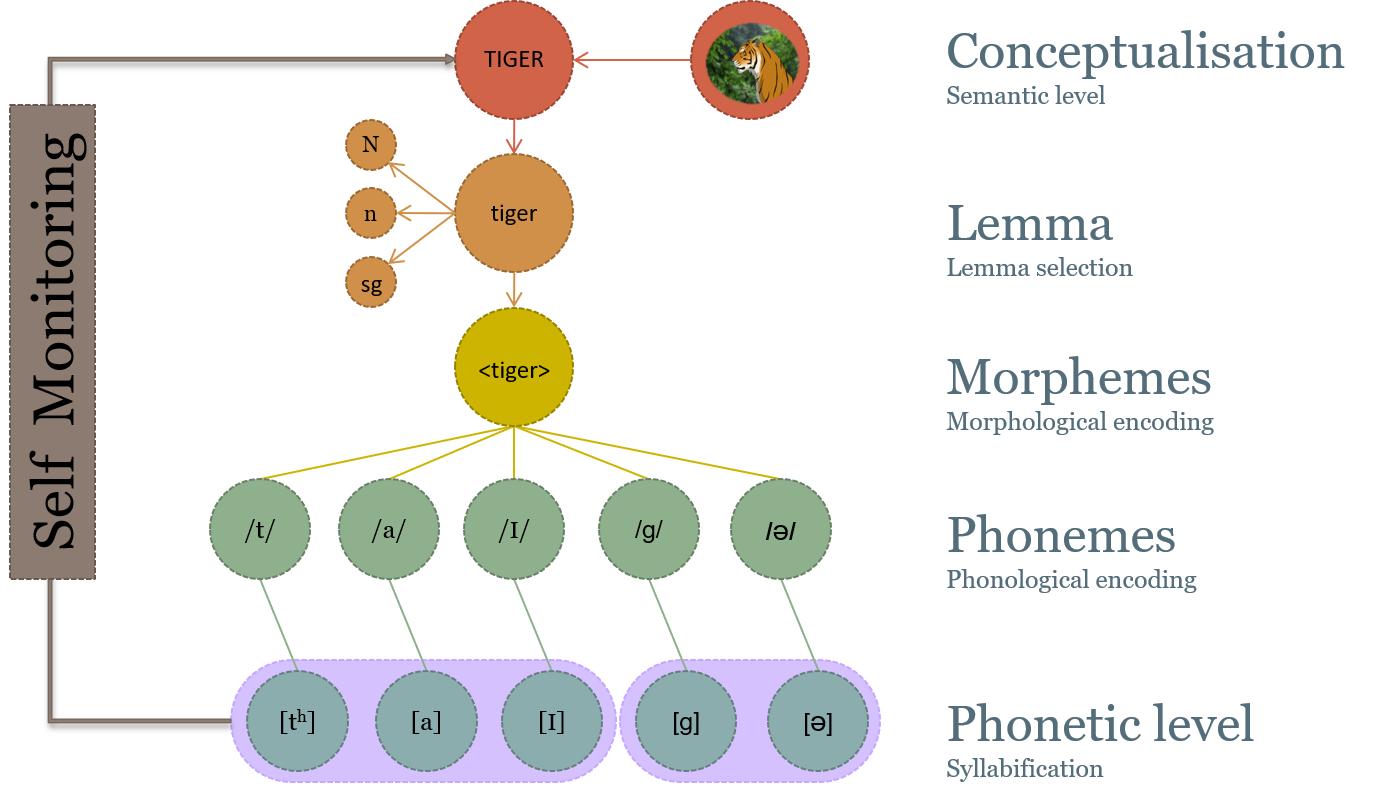
Morpheme Level
We have already seen (in Chapter 3) that morphemes are the smallest units of meaning. A word can be made up on one or more morphemes. Speech errors involving morphemes effect the lemma level or the wordform level (Dell, 1986) as in:
- “how many pies does it take to make an apple?” (Garrett, 1988)
- “so the apple has less trees” (Garrett, 2001)
- “I’d hear one if I knew it” (Garrett, 1980)
- “… slicely thinned” (Stemberger, 1985)
In the first, we see that the morpheme that indicates the plural number has remained in place while the morpheme for ‘apple’ and ‘pie’ exchanged. This is also seen in the last example. This suggests that the exchange occurred after the parameters for number were set indicating that lemmas can switch independent of their morphological and phonological representations (which occur further down in speech production).
Segment Level
While speech production models differ in their organisation and storage of segments, we will assume thay segments have to be retrieved at some level of speech production. Between 60-90% of all speech errors tend to involve segments (Boomer & Laver, 1968; Fromkin, 1971; Nooteboom, 1969; Shattuck-Hufnagel, 1983). However, 10-30% of all speech errors also involve segment sequences (Stemberger, 1983; Shattuck-Hufnagel, 1983). Reaction time experiments have also been employed to justify this level. Roeloffs (1999) asked participants to learn a set of word pairs followed by the first word in the pair being presented as a prompt to produce the second word. These test blocks were presented as either homogeneous or heterogenous phonological forms. In the homogenous blocks there were shared onsets or the segments differed only in voicing. In the heterogenous blocks the initial segments contrasted in voicing and place of articulation. He found that there were priming effects in homogenous blocks when the targets shared an initial segment but not when all but one feature was shared suggesting that whole phonological segments are represented at some level rather than distinctive features.
Phonetic Level
The segmental level we just discussed is based on phonemes. The standard understanding of speech is that there must be a phonetic level that represents the actual articulated speech as opposed to the stored representations of sound. We have already discussed this in Chapter 2 and will expand here. For example, in English, there are two realizations of unvoiced stops. One form is unaspirated /p/, /k/, and /t/ and the other is aspirated [ph], [kh], and [th]. This can be seen in the words pit [phɪt] and lip [lɪp] where syllable-initial stops are aspirated as a rule. The pronunciation of pit as *[pɪt] doesn’t change the meaning but will sound odd to a native speaker. This shows that /p/ has one phonemic value but two phonetic values: [p] and [ph]. This can be understood as going from an abstract level to a concrete level developing as speech production occurs. Having familiarized ourselves with the basic levels of speech production, we can now go on to see how they are realized in actual speech production models.
Image descriptions
Figure 9.2 The Standard Model of Speech Production
The Standard Model of Word-form Encoding as described by Meyer (2000), illustrating five level of summation of conceptualization, lemma, morphemes, phonemes, and phonetic levels, using the example word “tiger”. From top to bottom, the levels are:
- Semantic level: the conceptualization of “tiger” with an image of a tiger.
- Lemma level: select the lemma of the word “tiger”.
- Morpheme level: morphological encoding of the word tiger, t, i, g, e, r.
- Phoneme level: phonological encoding of each morpheme in the word “tiger”.
- Phonetic kevel: syllabification of the phonemes in the word “tiger”.
[Return to place in text (Figure 9.2)]
Media Attributions
- Figure 9.2 The Standard Model of Speech Production by Dinesh Ramoo, the author, is licensed under a CC BY 4.0 licence.
The process of forming a concept or idea.
The creation of the word form during speech production.
The formation of speech.
The process of developing a word for production.
The planning of word order in a sentence.
The form of a word or set of words.
