6.3 Models of Bilingualism
Dinesh Ramoo
The most influential model of bilingualism is the Bilingual Interactive Activation Plus (BIA+) model (Dijkstra & van Heuven, 2002; Dijkstra, van Heuven, & Grainger, 1998). The model tries to bring together evidence from bilingual orthographic processing as well as the recognition of words that look the same in two languages (cognates). The model is composed of a network of nodes at every level of representation from segmental (orthographic/phonemic), sub-lexical, to lexical. As seen in Figure 6.4, the model is bottom-up. Word recognition isn’t affected by whether the task is naming or reading.
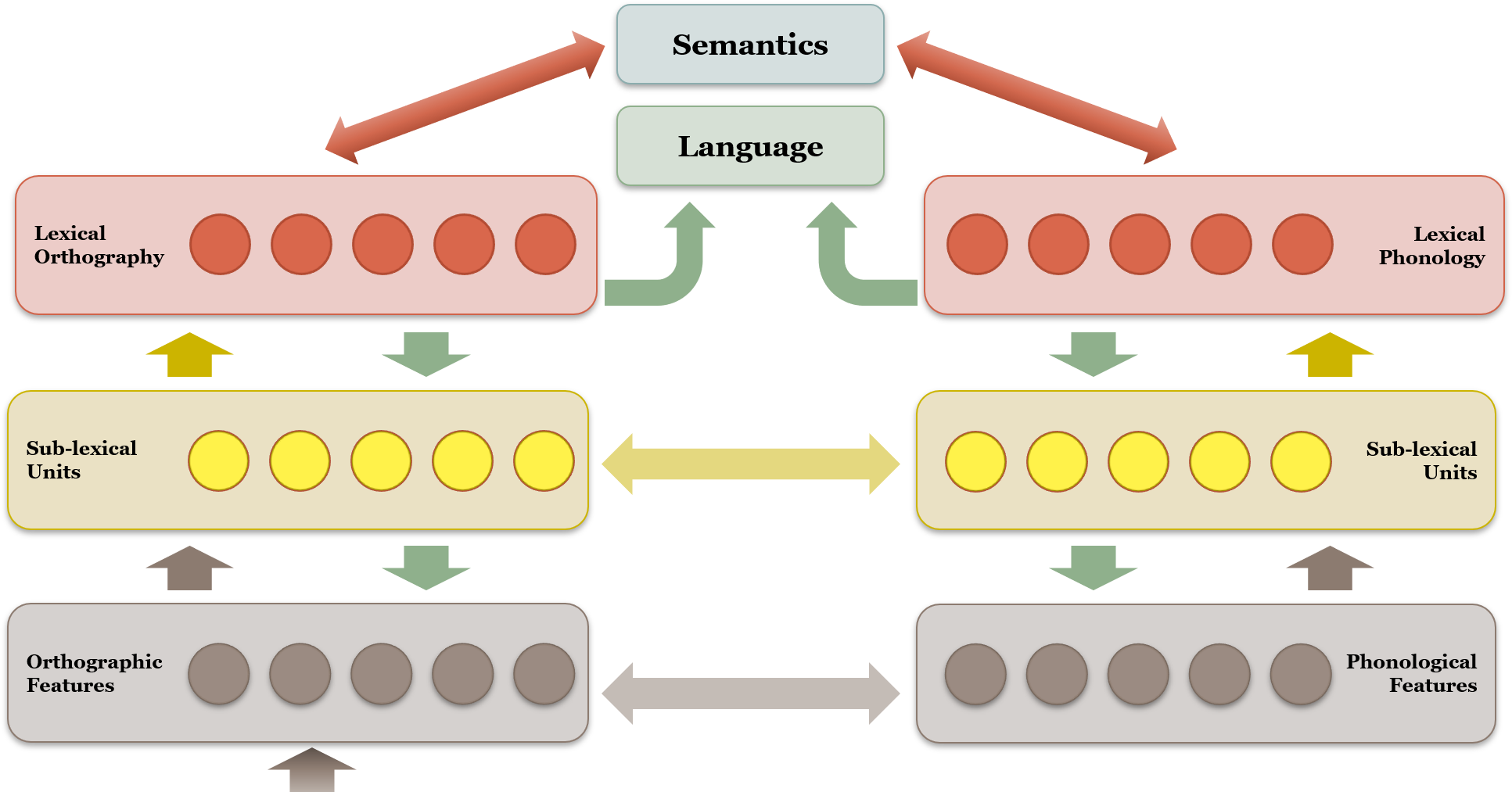
The model assumes a distinction between word identification and task-based sub-systems. The lexicon is integrated with parallel access as well as temporal decay of L2. This decay is based on the assumption that word frequency affects the resting potential of the nodes for particular words. The model is supported by neuroimaging studies. The Semantic, Orthographic, Phonological Interactive Activation (SOPHIA) model is the implemented version of the BIA+ model. It adds phonology and semantics with layers for letters/phonemes, clusters/ syllables/words and semantics. In SOPHIA, the language nodes no longer inhibit the non-target language. The model still uses orthographic information as input.
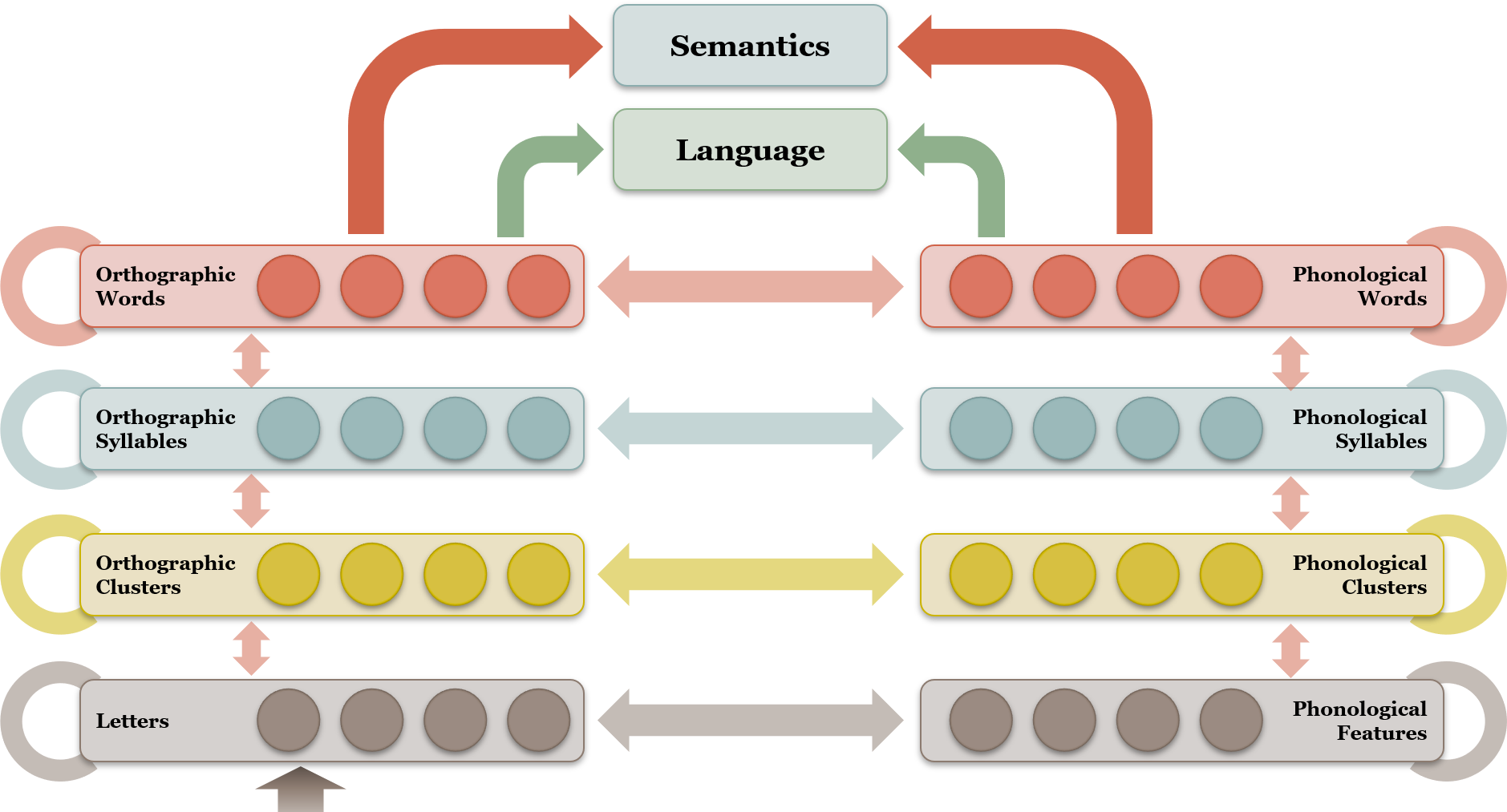
Image description
Figure 6.4 The Bilingual Interactive Activation Plus (BIA+) model
The BIA+ model is composed of three levels of representation. From bottom up the levels are orthographic or phonological features, followed by sub-lexical units, and then lexical orthography or lexical phonology, eventually lead to the semantic meaning of the language.
[Return to place in the text (Figure 6.4)]
Figure 6.5 The Semantic, Orthographic, Phonological Interactive Activation (SOPHIA) model
The SOPHIA model is composed of four layers of representation. From bottom up, the first layer of representation is letters or phonological features, followed by orthographic or phonological clusters, then orthographic or phonological syllables, and moving up to orthographic or phonological words, then eventually lead to the semantic meaning of the language.
[Return to place in the text (Figure 6.5)]
Media Attributions
- Figure 6.4 The Bilingual Interactive Activation Plus (BIA+) model by Dinesh Ramoo, the author, is licensed under a CC BY 4.0 licence.
- Figure 6.5 The Semantic, Orthographic, Phonological Interactive Activation (SOPHIA) model by Dinesh Ramoo, the author, is licensed under a CC BY 4.0 licence.
