8.1 Reading Models
Dinesh Ramoo
The Logogen Model
Proposed by Morton (1969, 1970), the Logogen model assumes units called logogens which are used to understand words that are heard and read. Logogens are specialized recognition units that are used for word recognition. Logogen is from the Greek λόγος (logos, word) and γένος (genos, origin). So, every word we know has its own logogen which contains phonemic and graphemic information about that word. As we encounter a word, the logogen for that word accumulates activation until a given threshold is reached upon which the word is recognized. An important issue to remember is that the logogen itself doesn’t contain the word. Rather, it contains information that can be used to retrieve the word. Accessing words is direct and parallel for all words.
Each logogen has a resting activation level. As it receives more evidence that corresponds to its word, this activation level increases up to a threshold. For example, if the input contains the grapheme <p>, then all logogens containing that visual input get an increase in activation. Once enough graphemes are there to fully activate the logogen it fires and word recognition occurs. The model is particularly good as including contextual information in recognizing words. One of the problems with this model was that it equated visual and auditory input for a word as using the same logogen process. A prediction of this model would be that a spoken prime should facilitate a written word just as much as a visual prime. However, experimental evidence contradicted this prediction (Winnick & Daniel, 1970). Following his own observation that confirms these findings, Morton divided the model into different sets of logogens (see Figure 8.1).
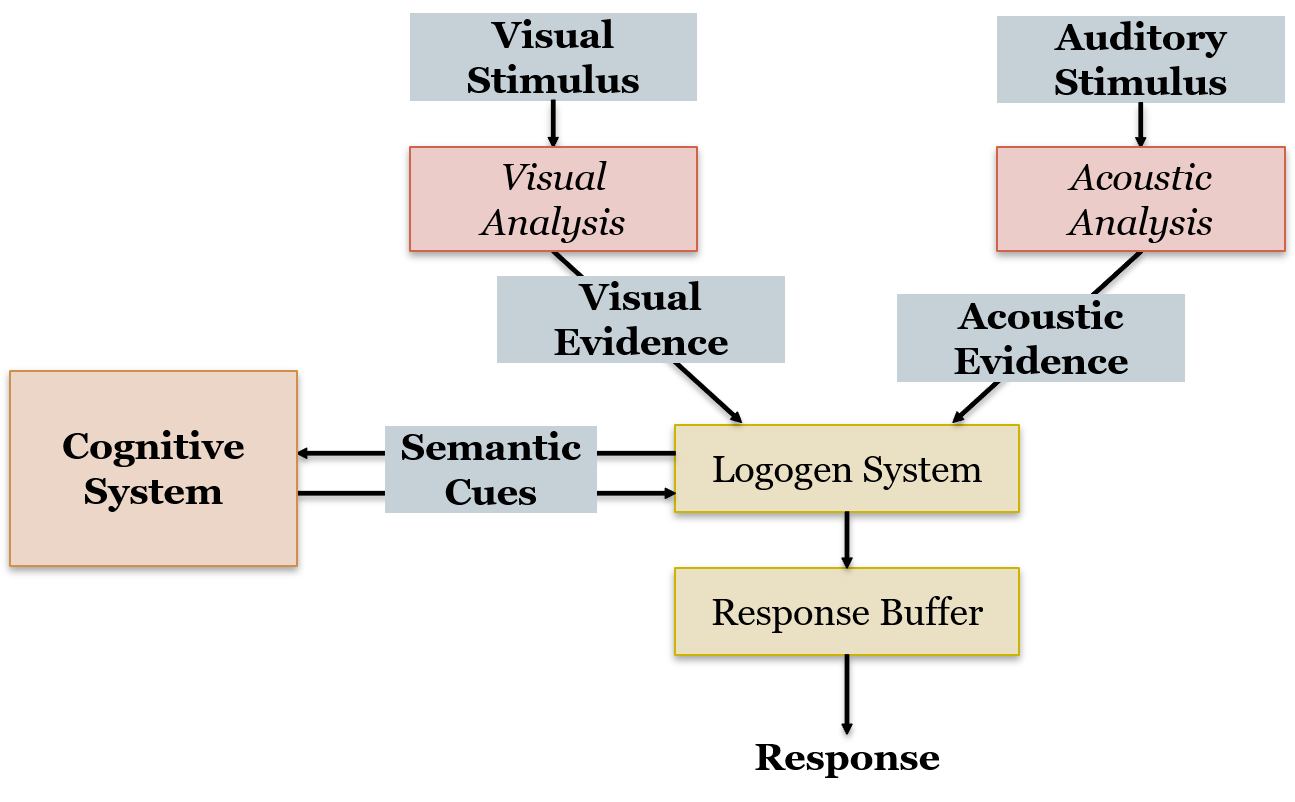
While the logogen model is quite successful in explaining word recognition in terms of semantics, there are some limitations to this model. There have been challenges to the existence of the logogen as a unit of recognition. Given that different pathways process information on the way to word recognition, is it really necessary to have such centralized units? The model’s limited scope for word recognition that ignores innate syntactic rules and grammatical construction is also a limitation.
Interactive Activation Model
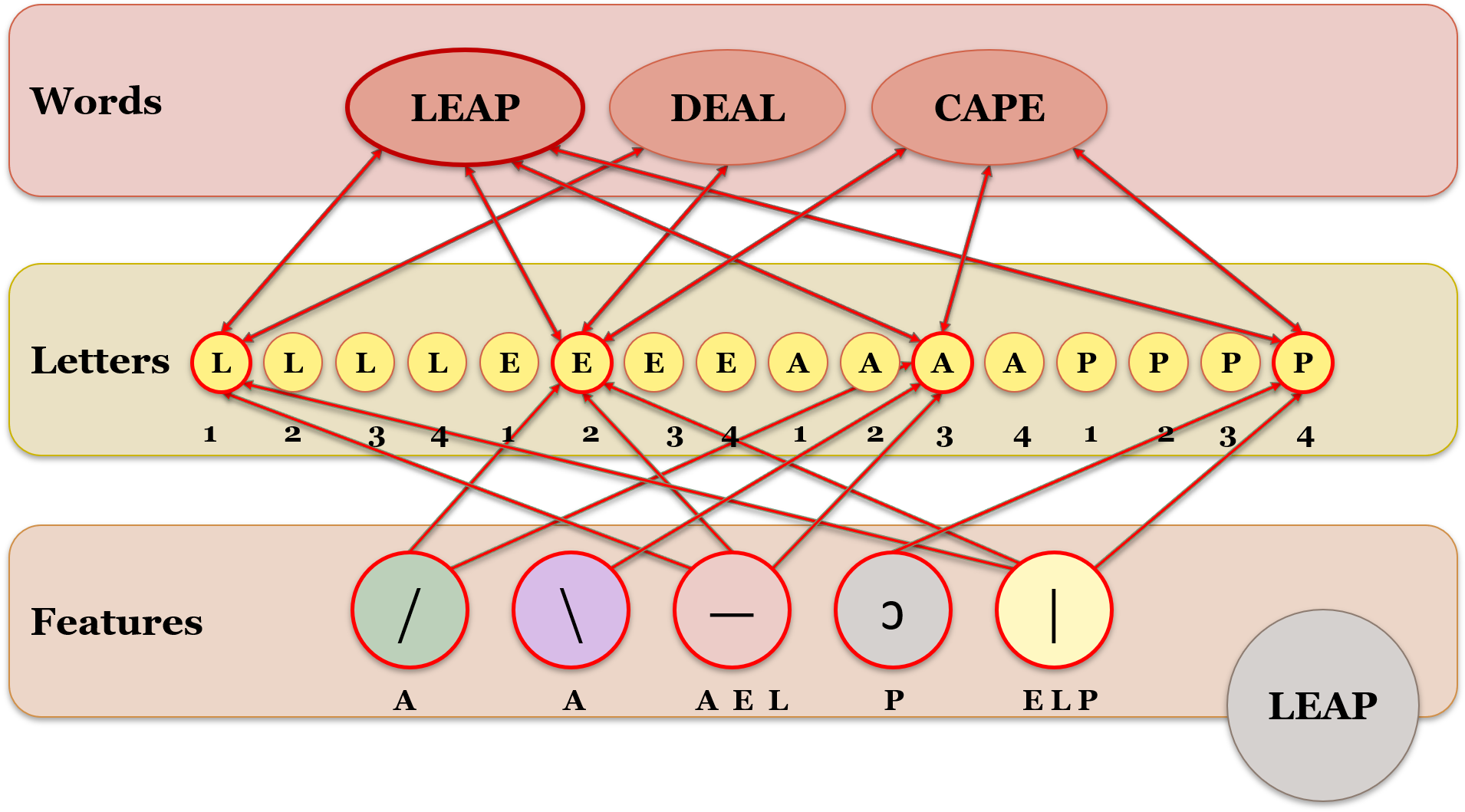
McClelland and Rumelhart (1981) and Rumelhart and McClelland (1982) developed the Interactive activation and competition (IAC) model. The model accounted for word context effects. This means that letters are easier to recognize if they are in words rather than as isolated letters (also known as the word superiority effect). As seen in Figure 8.3, the model consists of three levels: visual feature units, indivudla letter units, and word units. Each unit is connected to units in the level immediately before and after it with connections that are excitatory (if appropriate) or inhibitory (if inappropriate).
Let’s look at the example in Figure 8.3 for the word leap. First, the individual features are recognized. For example, the vertical line feature excites <E>, <P>, and <L> but combined with the horizontal line feature, it only excites <L>. All the letter units in turn excite words that contain them, but the words that do not contain the letters act as inhibitory signals in the opposite direction. Once enough letter units have accumulated activation of the word <LEAP>, then that word is recognized. The inhibition of units lower down the model if a positive recognition is not made accounts for the word superiority effect. Obviously, if no words are activated (if the letter is on its own), they will act as inhibitors in letter recognition. However, if the letter is within a word, then the words facilitate recognition.
Seidenberg and McClelland’s Model of Reading
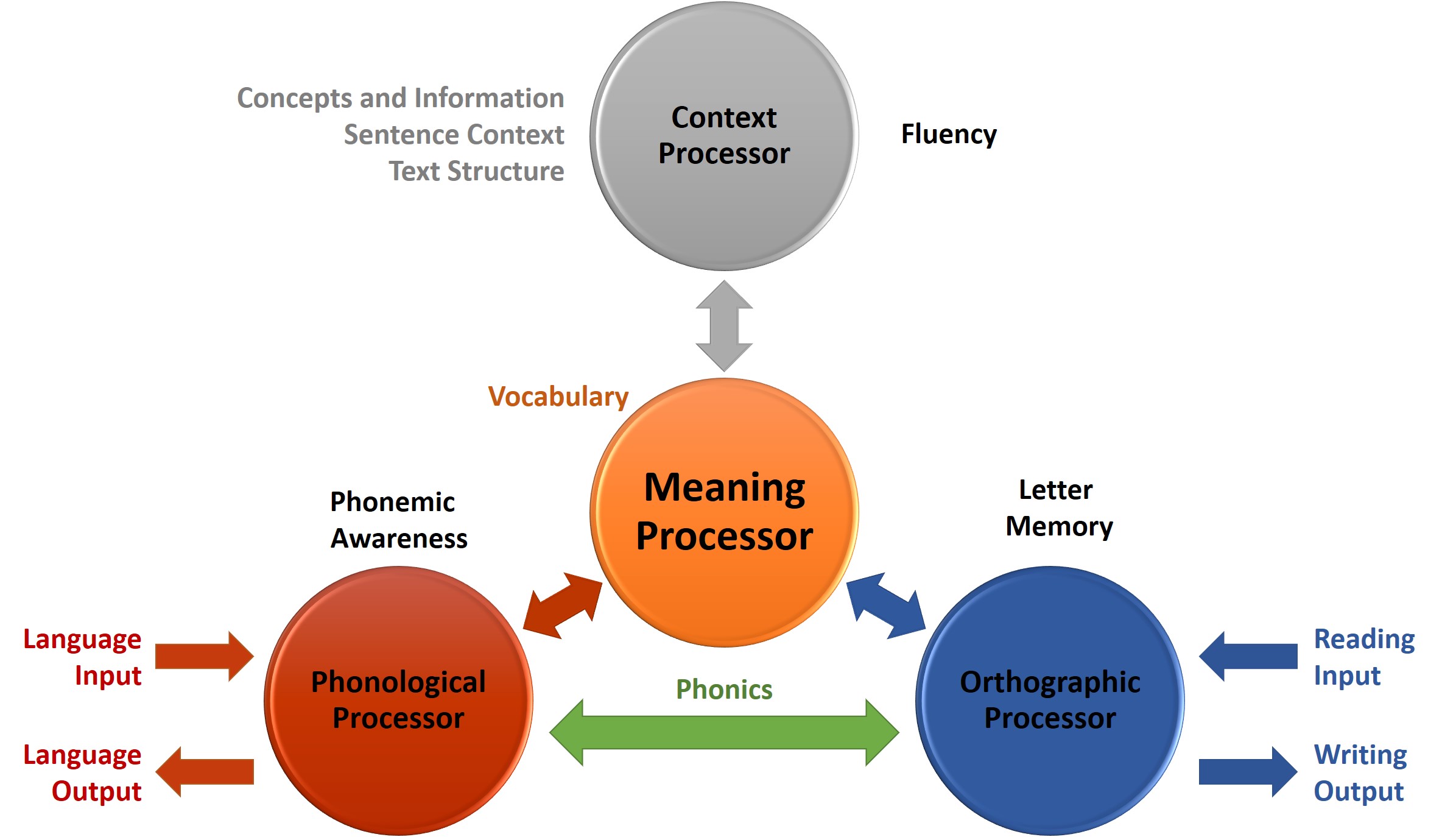
Seidenberg and McClelland (1989) proposed a model (also known as SM) that accounts for letter recognition and pronunciation. Reading and speaking involve three features: orthographic, semantic and phonological coding. In the SM model, these features are connected with feedback connections. As seen in Figure 8.2, the model is captured in a triangular shape. There is a route from orthography to phonology via semantics. However, there are no routes for grapheme-to-phonemes correspondence.
The model has three levels containing a number of simple units. These are the input, hidden and output layers. Each unit has an activation level and is connected to other units by weighted connections which can excite or inhibit activation. The main feature of these connections is that they are not set by anyone, but learned through back-propagation. This is an algorithmic method whereby the discrepancy between the actual output and the desired output is reduced by changing the weights between the connections. This model also does not have lexical entries for individual words. They are connections between phoneme or grapheme units.
Coltheart et al. (1993) criticized the SM model for not accounting for how people read exception words, and non-words. They also stated that the model doesn’t account for how people perform visual lexical decision tasks as well as failing to account for data from reading disorders
such as dyslexia. Forster (1994) pointed out that just because a model can successfully replicate reading data using connectionist modelling doesn’t mean that it reflects how reading occurs in human beings. Norris (1994) argued that the model doesn’t reflect how readers can shift strategically between lexical and non-lexical information when reading.
Dual-Route Model
The dual-route model is perhaps the most widely studied model for reading aloud. It assumes two separate mechanisms for reading: the lexical route and the non-lexical route. As seen in Figure 8.4, the lexical route is most effective with skilled readers who can recognize words that they already know. This is like looking for words in a dictionary. When a reader sees a word, they access the word in their mental lexicon and retrieve information about its meaning and pronunciation. However, this route cannot provide any help if you come across a new word for which there is not entry in the mental lexicon. For this you would need to use the non-lexical route.
The non-lexical or sub-lexical route is a mechanism for decoding novel words using existing grapheme-to-phoneme rules in a language. This mechanism operates through the identification of a word’s constituent parts (such as graphemes) and applying linguistic rules to decoding. For example, the grapheme <ch> would be pronounced as /tʃ/ in English. This route can be used to read non-words or regular words (that have regular spelling).
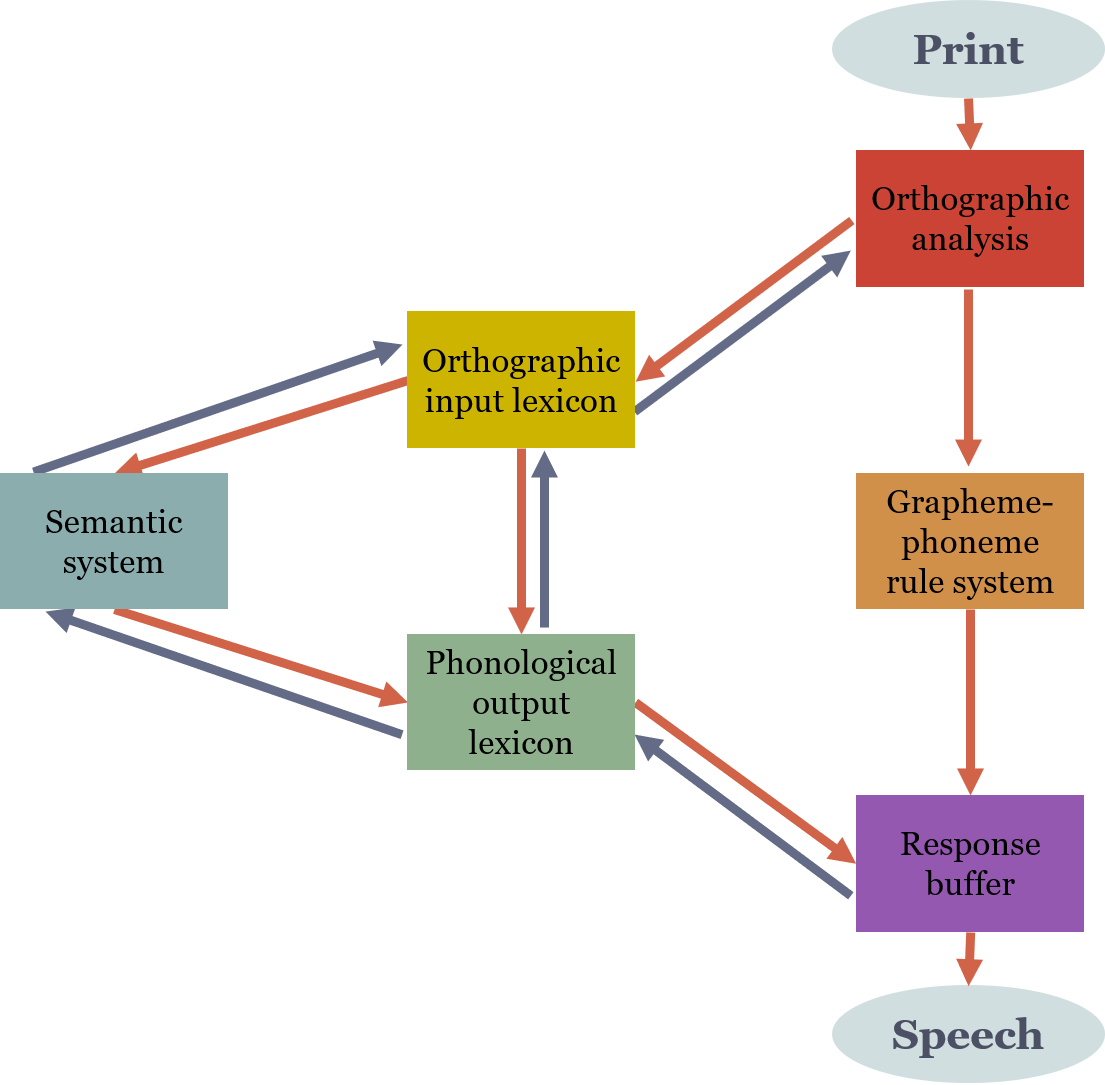
Image descriptions
Figure 8.3 Seidenberg and McClelland’s model of reading
The SM model is in a triangular shape. The three corners are:
- Context processor: processes concepts and information, sentence context and text structure, relates to the fluency of reading.
- Phonological processor: processes language input and output, relates to phonemic awareness.
- Orthographic processor: processes reading input and writing output, relates to letter memory.
Phonological processor and orthographic processor are connected by phonics, all three processors are connected by the meaning processor.
[Return to place in the text (Figure 8.3)]
A flow chart of the dual-route model that has a lexical route and a sub-lexical route for reading aloud.
- The lexical route: when a reader sees a print word they recognize, they start by orthographic analysis, then retrieve information from their orthographic input lexicon, semantic system, and phonological output lexicon, leading to a response buffer, and produce the speech.
- The sub-lexical route: when the reader sees a novel word, they start by orthographic analysis, then use the grapheme-phoneme rule system to decode the word, leading to a response buffer, and produce the the speech.
[Return to place in the text (Figure 8.4)]
Media Attributions
- Figure 8.1 Logogen Model by Dinesh Ramoo, the author, is licensed under a CC BY 4.0 licence.
- Figure 8.3 Seidenberg and McClelland’s model of reading by Dinesh Ramoo, the author, is licensed under a CC BY 4.0 licence.
- Figure 8.2 The Interactive Activation Model by Dinesh Ramoo, the author, is licensed under a CC BY 4.0 licence.
- Figure 8.4 Dual-Route Model by Dinesh Ramoo, the author, is licensed under a CC BY 4.0 licence.
A speech recognition model that used units called logogens to explain word comprehension.
A model for representing memory in artificial intelligence networks. Usually comprised of three levels of interacting components of increasing complexity.
In artificial intelligence neural networks, an error correction method whereby the output is fed back as an input into the system.
A reading model that proposes two separate paths for reading aloud; a lexical route and a sub-lexical route.
In the dual-route model, the pathway that processed whole words.
In the dual-route model. The pathway that processed words using grapheme-to-phoneme conversion.
In the dual-route model. The pathway that processed words using grapheme-to-phoneme conversion.
