3.3 Morphology of Different Languages
Dinesh Ramoo
The way in which morphemes are employed to modify meaning can vary between languages. Morphological typology is a method used by linguists to classify languages according to their morphological structure. While a variety of classification types have been identified, we will look at a common method of classification: analytic, agglutinative and fusional. Figure 3.2 give some examples of morphological typology across the world’s languages.
Analytic languages have a low ratio of morphemes to words. They are often isolating languages in that each morpheme is also a word and vice versa. These languages create sentences with independent root morphemes with grammatical relations between words being expressed with separate words. Examples of analytics or isolating languages include Chinese languages and Vietnamese. While in English we inflect numbers: one day, two days, an analytic language such as Mandarin Chinese has no inflection: 一天, yì tiān “one day”, 三天, sān tiān “three day”. The Canadian linguist and translator Sonja Lang has created an analytic language, Toki Pona, as a minimalist creative endeavour.
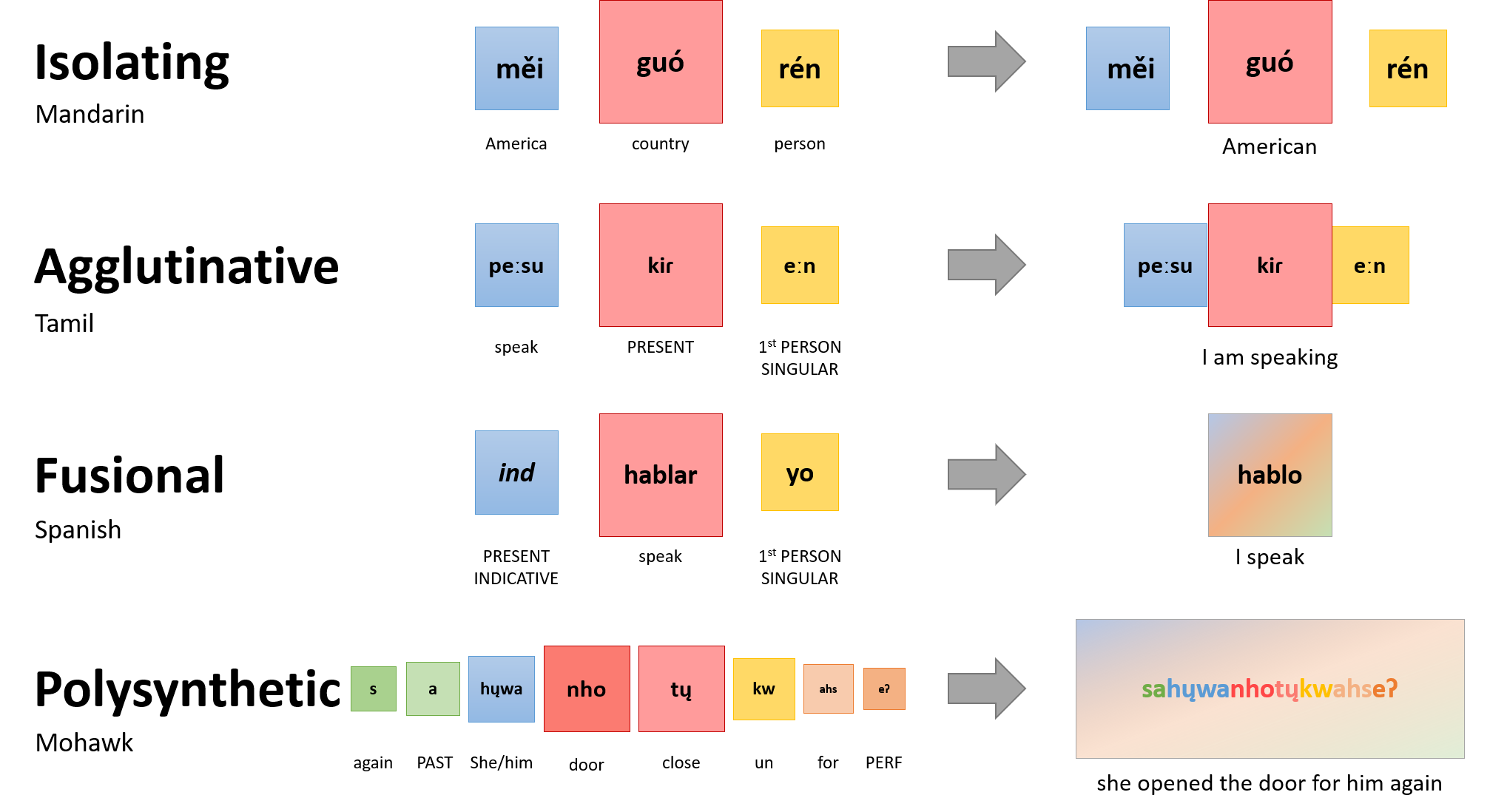
Unlike analytic languages, synthetic languages employ inflection or agglutination to express syntactic relationships. Agglutinative languages combine one or more morphemes into one word. The distinguishing feature of these languages is that each morpheme is individually identifiable as a meaningful unit even after combining into a word. Examples of agglutinative languages include Tamil, Secwepemc, Turkish, Japanese, Finnish, Basque and Hungarian. Figure 3.3 shows you an example of agglutination in Turkish. Each coloured morpheme is also given an approximate English translation. Figure 3.2 give another example from Tamil.

Another type of synthetic languages are fusional languages. Like agglutinative languages, fusional languages also combine morphemes to modify meaning. However, these combinations often do not remain distinct and fuse together. In addition, these languages also have a tendency to use a single inflectional morpheme to denote numerous grammatical or syntactic features. For example, the suffix -í in Spanish comí (“I ate”) denotes both first-person singular agreement and preterite tense. Examples of fusional languages include Indo-European languages such as Sanskrit, Spanish, Romanian, and German. Modern English could also be considered fusional; although it has tended to evolve to be more analytic. J. R. R. Tolkien’s fictional language Sindarin is fusional (another elvish language, Quenya, is agglutinative).
Figure 3.2 shows an additional morphological type named polysynthetic. These languages tend to a high morpheme-to-word ratio as well as regular morphology. They often combine a large number of morphemes to form words that are the equivalent of entire sentences in other languages. Many languages in North America such as Mohawk tend to have this type of morphology.
Inflectional Morphology
Inflectional morphemes add grammatical information to a word while retaining its core meaning and its grammatical category. The tense of a verb is indicated by inflectional morphology. You add -ed to walk to make walked. You can also make a past tense inflection through the change of a vowel as in sang or wrote. Some languages have inflections for the future tense as well (which English does not have). Another example is when you indicate number in English by adding -s to a word you add the morpheme to the end of a singular noun. So, book can be made a plural by adding -s to make it books. The original stem doesn’t change in meaning and it remains a noun. While English only has singular and plural numbers, some languages have a dual number. Consider the following example from Ancient Greek (Weir, 1920):
ὁ θεός (ho theós) “the god” (singular)
τὼ θεώ (tṑ theṓ) “the two gods” (dual)
οἱ θεοί (hoi theoí) “the gods” (plural)
Inuktitut spoken in the territory of Nunavut also has a dual number (Anderson, 2018):
| Inuktitut | English translations |
|---|---|
| matu | door |
| matuuk | doors (two) |
| matuit | doors (three or more) |
| nuvuja | cloud |
| nuvujaak | clouds (two) |
| nuvujait | clouds (three or more) |
| qarasaujaq | computer |
| qarasaujaak | computers (two) |
| qarasaujait | computers (three or more) |
Derivational Morphology
Another way in which morphemes modify meaning is through derivation. Here the original word is modified by the derivation and often changes its word category. Form example, adding -er to the verb write will modify it into a noun: writer. The same is seen in teacher, walker and baker. In the same way, an adjective can be changed into a noun as in sad and –ness becoming sadness.
Derivation often leads to the creation of new words. These new words can in turn serve as a base for further derivation. This can lead to some rather complex morphological forms. For example, a machine that computes may be called a computer (compute and -er). When we use a computer to complete a task, we could say they computerize (computer and -ize) which in turn can be called computerization (computerize and -ation). One interesting observation is that inflecting a base makes further derivation impossible. So, making a plural our of computer into computers (computer and -s) means we cannot make it into *computersize.
Nonconcatenative Morphology
Most of the morphological types we have seen make use of prefixes and suffixes to make changes in meaning. These involve making sequential changes to the stem. However, there are some languages that make morphological modifications to a word-root using non-sequential methods. This is known as nonconcatenative morphology, discontinuous morphology or introflection. This type of change is also seen in English foot /fʊt/ → feet /fiːt/ as well as freeze /ˈfriːz/ → froze /ˈfroʊz/, frozen /ˈfroʊzən/. While these rare cases exist in other Indo-European languages as well, this is very well developed in Semitic languages such as Arabic. Consider some derivation of the Semitic root k-t-b in Arabic (Wehr, 1994) and Hebrew. This root is transposed into other segments to create these morphological derivations.
| Arabic | Transliteration | Hebrew | Transliteration | Translation |
| كتب | kataba | כתב | kataḇ | ‘he wrote’ |
| كَتَبْتُ | katabtu | כתבתי | kāṯaḇti | ‘I wrote’ |
| كاتب | kātib | כותב | koteḇ | ‘writer’ |
| أكتب | ʾaktaba | הכתיב | hiḵtiḇ | ‘he dictated’ |
| مكتب | maktab | מכתב | miḵtaḇ | ‘office’ (Arabic), ‘letter’ (Hebrew) |
| استكتب | istaktaba | התכתב | hitkatteḇ | ‘he made (them) write’ (Arabic),
‘he corresponded’ (Hebrew) |
As we can see, the morphemes do not attach to the ends but infuse within the triconsonantal roots as infixes. Figure 3.4 and Figure 3.5 illustrate how this can be visualized from a language production standpoint. We see the consonantal roots act as separate morphemes from the infixes which intertwine to form the final segmental sequence that is syllabified and spoken. This shows us that morphology can be more complex than simple additions to a stem.
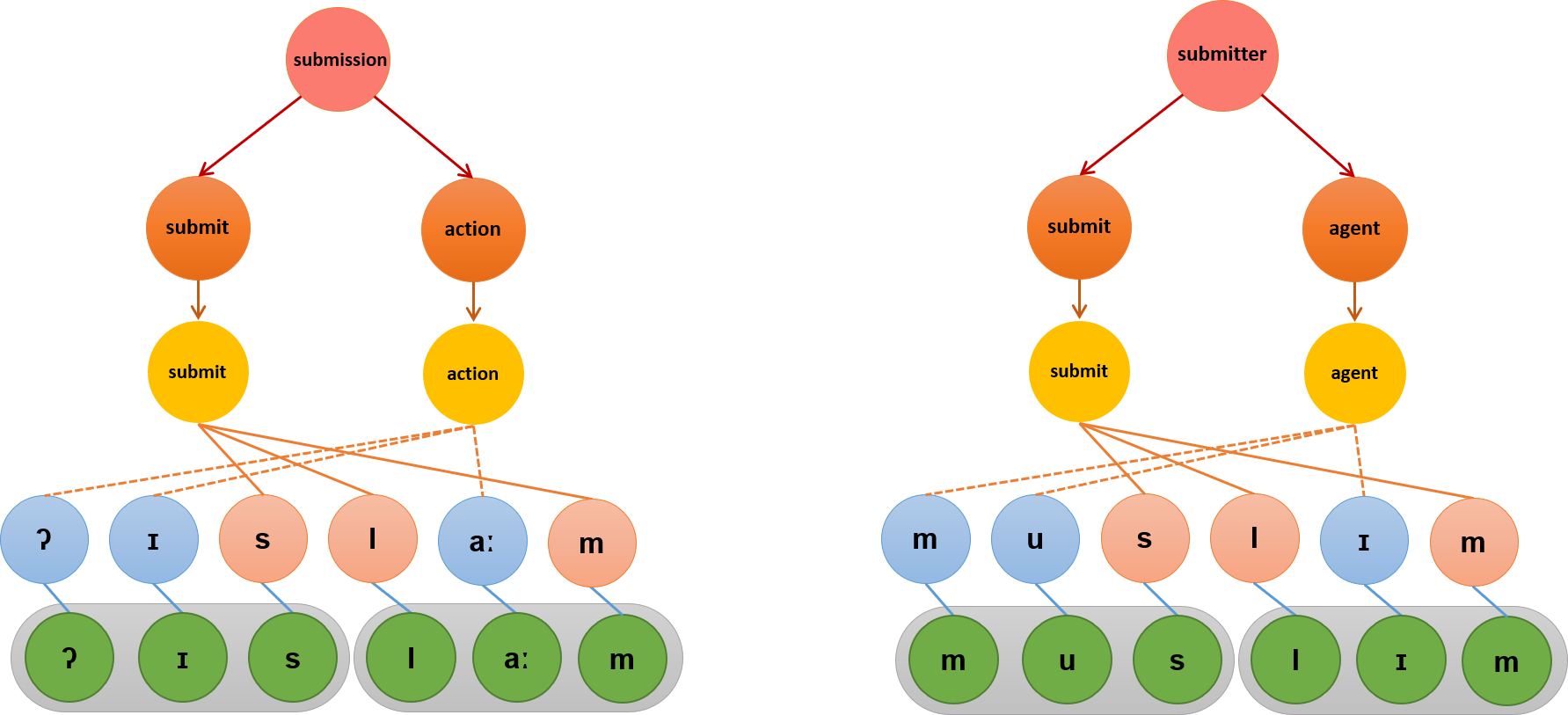
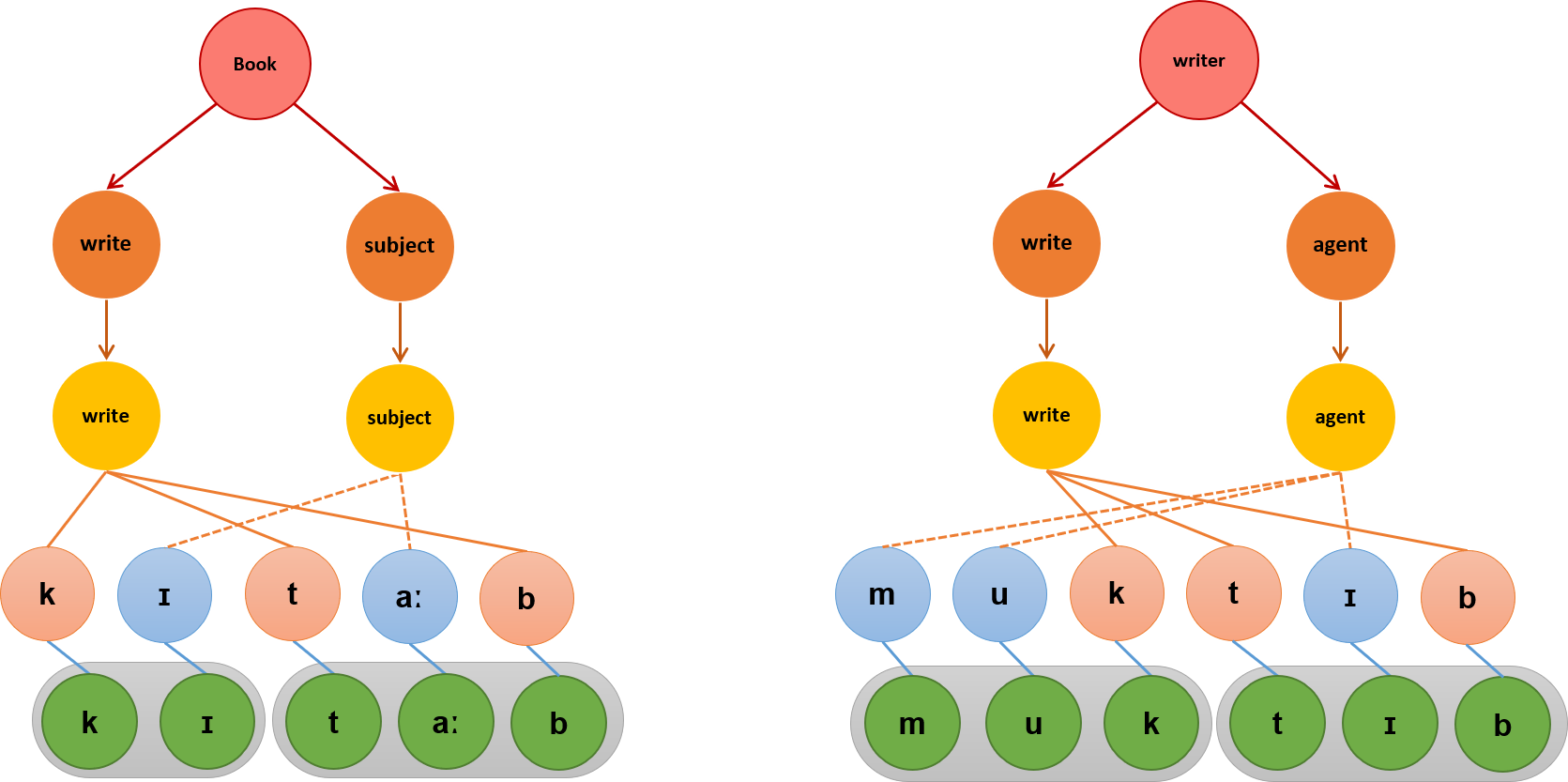
Image description
Figure 3.2 Examples of Morphological Typology
Provides examples of the morphological typology of Mandarin, isolating language, Tamil, an agglutinative language, Spanish, a fusional language, and Mohawk, a polysynthetic language. The image illustrates the meanings of the morpheme components of the words or phrases, and how they combine to express meaning.
- Isolating language (Mandarin): měi (America), guó (country), and rén (person) combined into měi guó rén which means “American”.
- Agglutinative language (Tamil): peːsu (speak), kir (present), and eːn (1st person singular) combined into peːsu kir eːn which means “I am speaking”.
- Fusional (Spanish): ind (present indicative), hablar (speak) and yo (1st person singular) combined into hablo which means “I speak”.
- Polysynthetic (Mohawk): s (again), a (past), hųwa(she/him), nho (door), tų (close), kw (un), ahs (for), eʔ (perfective) combined into sahųwanhotųkwahseʔ which means “she opened the door for him again”.
[Return to place in text (Figure 3.2)]
Figure 3.3 Example from Turkish, an Agglutinative Language
Two examples of agglutination from the Turkish language broken down into their morphological components.
- Adamla tanıştım – “I met with the man”
- Adam – indirect object
- la – instrumental case suffix
- tanış – verb stem
- tı – past tense suffix
- m – indicator of subject
- Adamın kitabı – “Man’s book”
- Adam – possessor
- ın – genitive suffix
- kitab – possessed noun
- ı – possessive ending
[Return to place in text (Figure 3.3)]
Media Attributions
- Figure 3.2 Examples of Morphological Typology by Dinesh Ramoo, the author, is licensed under a CC BY 4.0 licence.
- Figure 3.3 Example from Turkish, an Agglutinative Language by Dinesh Ramoo, the author, is licensed under a CC BY 4.0 licence.
- Figure 3.4 Non-concatenative Morphology in Arabic by Dinesh Ramoo, the author, is licensed under a CC BY 4.0 licence.
- Figure 3.5 Non-concatenative Morphology in Arabic by Dinesh Ramoo, the author, is licensed under a CC BY 4.0 licence.
A method of classifying languages based on their common methods for modifying morphemes.
A language that primarily employs helper words and word order to show the relationship between words.
A language that mostly has isolated morphemes as words with no inflectional morphology.
A language which primarily employs agglutination (sticking morphemes together) in its morphology.
Another name for a language that employs inflectional morphology.
A language which has words composed of many morphemes.
The process of changing word meaning through affixation and vowel change.
A linguistic category that expresses time reference.
A grammatical category that expresses count distinctions (e.g., one versus many).
Forming a new word from an existing word through the addition of a prefix or suffix.
A type of morpheme modification that involves modifying the root without sequentially stringing units one after the other.
